

Migration guide
0.17
Breaking changes
Updated system requirements
Ponder now requires Node.js >=22, TypeScript >=5.4.0, and Viem >=2.35.0.
pnpm add viem@^2.35.0
pnpm add --save-dev typescript@^5.4.0New features
Factory cache fix
Ponder now correctly invalidates cached factory intervals after a factory config change. Apps upgrading directly from 0.14 or earlier, and apps affected by this bug, may perform a one-time refetch of the affected block range. No database migration is required.
Co-located test files
Test files can now be co-located with indexing functions. Files matching *.test.{ts,js,mts,mjs} or *.spec.{ts,js,mts,mjs} in the indexing directory are ignored when Ponder loads indexing functions.
Anonymous telemetry removed
Ponder no longer collects anonymous telemetry.
0.16
Breaking changes
Table and schema name length limits
The onchainTable name, --schema CLI option, and --views-schema CLI option now enforce a maximum length of 45 characters. This eliminates an issue where names could conflict undetected and cause undefined behavior.
Other values like column names, onchainView name, and index names are unaffected and will continue to use the default Postgres behavior (maximum of 63 characters with truncation).
Removed Etherscan and subgraph templates
The create-ponder CLI tool no longer supports bootstrapping a project from an Etherscan or subgraph link. Both options have been broken for some time due to breaking changes to upstream APIs.
New features
Bun support
Ponder now officially supports the Bun runtime. Read more in the new guide.
Live indexing performance improvement
During live indexing, the Store API now uses the same in-memory database as it uses during backfill indexing. This dramatically improves live indexing performance for high-throughput projects (~50+ database operations per second). If your project was struggling to keep up with tip during live indexing, this release may solve your problem.
Full node-postgres poolConfig support
Ponder now supports the full range of node-postgres poolConfig options.
import { createConfig } from "ponder";
export default createConfig({
database: {
kind: "postgres",
poolConfig: {
// ... config options
},
},
});0.15
Breaking changes
None.
New features
ordering: "experimental_isolated"
A new ordering mode, experimental_isolated, is available. This mode isolates each chain, requiring each table in the schema to include a chain_id column in the primary key. It also takes advantage of mulitple CPU cores for better performance.
Visit the documentation for details.
Improved SQL over HTTP scalability
SQL over HTTP queries are cached and selectively invalidated only when a table referenced by the query is updated.
Live queries are now guaranteed to be updated only when the query result changes.
0.14
Breaking changes
Metrics updates
- Removed the
ponder_historical_duration,ponder_indexing_has_error, andponder_http_server_portmetrics. - Added a
chainlabel toponder_historical_start_timestamp_secondsandponder_historical_end_timestamp_seconds. - Updated histogram bucket limits.
New features
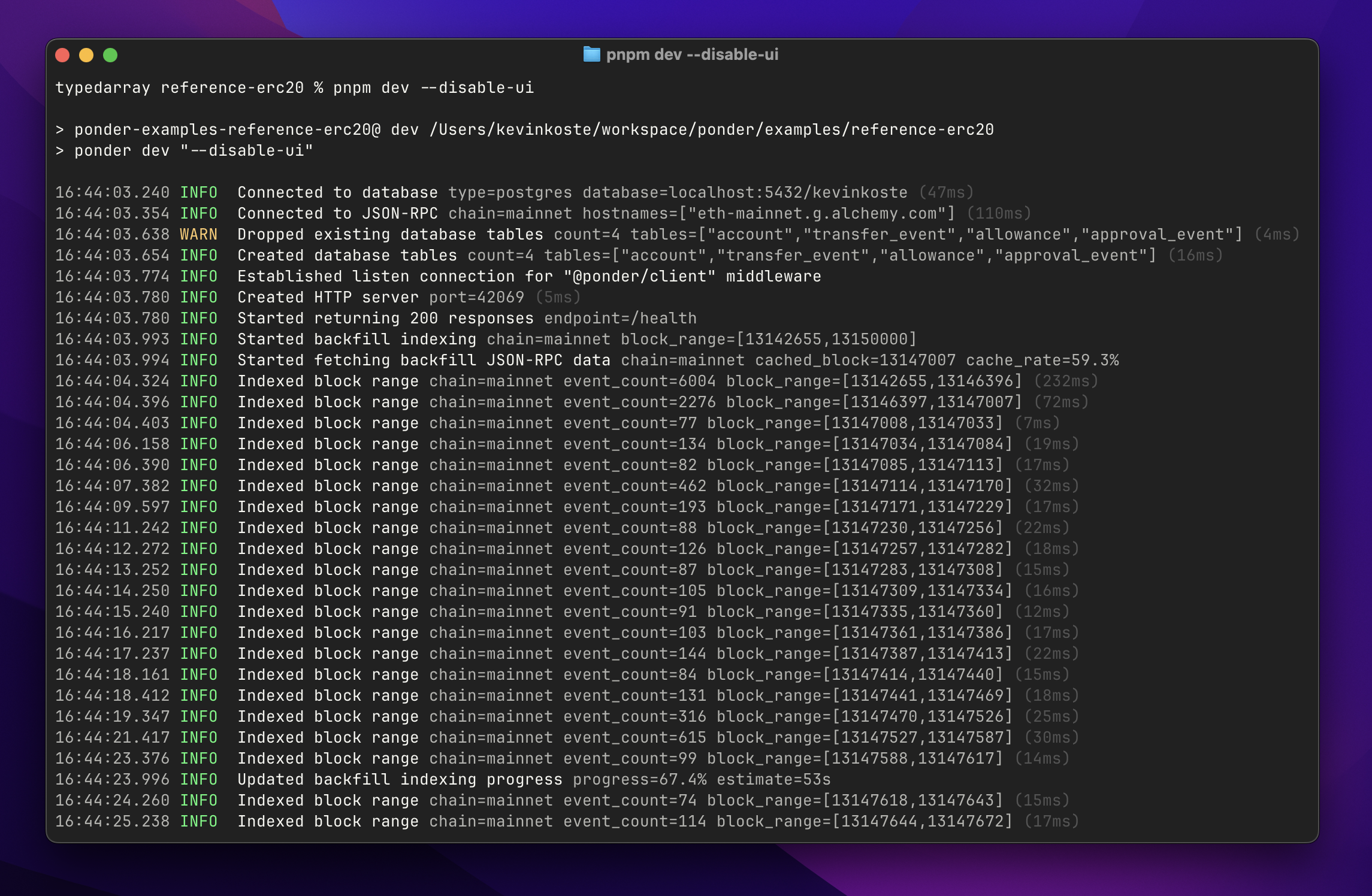
Log output improvements
Ponder now emits a more useful set of logs. These changes improve signal-to-noise and aim to eliminate scenarios where Ponder appears to hang without printing any logs.
Highlights:
- Pretty logs (the default) now use millisecond precision for timestamps, no longer include a "service" column, and use logfmt formatting for extra properties.
- JSON-formatted logs (
--log-format jsonCLI option) now include a wider range of properties, e.g.duration,block_range,chain_id, and so on. The standardserviceproperty was removed.
GraphQL offset pagination
The GraphQL now supports offset pagination for each plural query field and many() relationship field.
Read more in the GraphQL pagination docs.
Custom database views
Ponder now supports custom database views in ponder.schema.ts that reference other tables or views in your schema. Custom views are defined using the Drizzle query builder API.
We expect this feature to be particularly useful for users who want custom query-time transformation logic but still prefer GraphQL (vs. SQL-over-HTTP or direct SQL).
Read more in the custom view guide.
0.13
Breaking changes
None.
New features
Performance
Ponder now queries less data from the database when reindexing against a full RPC cache. This can eliminate a significant amount of unnecessary work for apps with a large number of events where the indexing logic only accesses a few properties on the event object.
0.12
Breaking changes
Lowercase addresses
Address values on the event object are now always lowercase. Before, these values were always checksum encoded.
This includes decoded event and trace arguments (e.g. event.args.sender) and these standard properties of the event object:
event.block.minerevent.log.addressevent.transaction.toevent.transaction.fromevent.transactionReceipt.fromevent.transactionReceipt.toevent.transactionReceipt.contractAddressevent.trace.fromevent.trace.to
New features
Exit code 75
Ponder now exits with code 75 when the instance encounters a retryable error. This includes most RPC errors and database connection issues.
Exit code 1 now indicates a fatal error that is unlikely to resolve after a restart. This includes logical indexing errors (e.g. unique constraint violations).
0.11
Breaking changes
Renamed networks → chains
The networks field in ponder.config.ts was renamed and redesigned.
networks→chainschainId→idtransport→rpc
The new rpc field accepts one or more RPC endpoints directly, or a Viem Transport for backwards compatibility. When multiple RPC URLS are provided, Ponder load balances across them.
import { createConfig } from "ponder";
import { http } from "viem";
export default createConfig({
networks: {
mainnet: {
chainId: 1,
transport: http("https://eth-mainnet.g.alchemy.com/v2/your-api-key"),
},
},
chains: {
mainnet: {
id: 1,
rpc: "https://eth-mainnet.g.alchemy.com/v2/your-api-key",
},
},
contracts: {
Erc20: {
network: "mainnet",
chain: "mainnet",
// ...
}
}
});Renamed context.network → context.chain
The indexing function context object context.network was renamed to context.chain.
Renamed API functions → API endpoints
API functions were renamed to API endpoints throughout the documentation.
publicClients now keyed by chain name
The publicClients object (available in API endpoints) is now keyed by chain name, not chain ID.
/status response type
The response type for the /status endpoint and related functions from @ponder/client and @ponder/react has changed.
type Status = {
[chainName: string]: {
ready: boolean;
id: number;
block: { number: number; timestamp: number };
};
};Default multichain ordering
The default event ordering strategy was changed from omnichain to multichain. Read more about event ordering.
New features
Database views pattern
This release introduces a new pattern for querying Ponder tables directly in Postgres. Read more about the views pattern.
Update start command
To enable the views pattern on platforms like Railway, update the start command to include the new --views-schema flag.
pnpm start --schema $RAILWAY_DEPLOYMENT_ID
pnpm start --schema $RAILWAY_DEPLOYMENT_ID --views-schema my_projectWhenever a deployment becomes ready (historical indexing finishes), it will create views in the specified schema that "point" to its tables.
Query views schema
With this configuration, downstream applications can query the views schema directly. The views will always point at the latest deployment's tables.
SELECT * FROM my_project.accounts;0.10
Breaking changes
ponder_sync database migration
WARNING: This release includes an irreversible database migration to the RPC request cache located in the ponder_sync schema. Here are some details to consider when upgrading your production environment.
- When an
0.10instance starts up, it will attempt to run the migration against the connected database. - Any
<=0.9instances currently connected to the database will crash, or the migration will fail. - Once the migration is complete, it's not possible to run
<=0.9instances against the upgraded database.
Removed event.log.id
The event.log.id and event.trace.id properties were removed. Replace each occurrence with the new event.id property (described below), or update the table definition to use a compound primary key that better represents the business logic / domain.
import { ponder } from "ponder:registry";
import { transferEvent } from "ponder:registry";
ponder.on("ERC20:Transfer", ({ event, context }) => {
await context.db
.insert(transferEvent)
.values({ id: event.log.id });
.values({ id: event.id });
});Removed event.name
The undocumented event.name property was also removed.
New features
event.id
The new event.id property is a globally unique identifier for a log, block, transaction, or trace event that works across any number of chains. Each event.id value is a 75-digit positive integer represented as a string.
Factory performance
This release fixes a long-standing performance issue affecting large factory contracts (10k+ addresses). Before, a SQL query was used to dynamically generate the list of addresses for each batch of events. This did not scale well. Now, the list of addresses is materialized directly and all address filtering occurs in-memory.
RPC request cache fixes
This release fixes two performance issues related to the ad-hoc RPC request cache.
- Reorg reconciliation — Before, the query that evicted non-canonical results from the cache did not have an appropriate index. This occasionally caused timeouts leading to a crash.
- Large multicalls — Before, multicall requests were treated naively as a single large
eth_call. Now, the caching logic intelligently splits large multicall requests into smaller chunks.
0.9
Breaking changes
API endpoints file is required
The Hono / API endpoints file src/api/index.ts is now required. The GraphQL API is no longer served by default.
To achieve the same functionality as <=0.8, copy the following code into src/api/index.ts.
import { db } from "ponder:api";
import schema from "ponder:schema";
import { Hono } from "hono";
import { graphql } from "ponder";
const app = new Hono();
app.use("/", graphql({ db, schema }));
app.use("/graphql", graphql({ db, schema }));
export default app;Removed ponder.get(), post(), use()
This release makes custom API endpoints less opinionated. Just default export a normal Hono App object from the src/api/index.ts file, and Ponder will serve it.
The ponder.get(), post(), use() methods were removed. Now, use Hono's built-in routing system.
import { ponder } from "ponder:registry";
ponder.get("/hello", (c) => {
return c.text("Hello, world!");
});Removed c.db
The c.db object was removed from the Hono context. Now, use the "ponder:api" virtual module to access the readonly Drizzle database object.
import { db } from "ponder:api";
import schema from "ponder:schema";
import { Hono } from "hono";
const app = new Hono();
app.get("/account/:address", async (c) => {
const address = c.req.param("address");
const account = await db
.select()
.from(schema.accounts)
.where(eq(schema.accounts.address, address))
.limit(1);
return c.json(account);
});
export default app;New features
SQL over HTTP
The @ponder/client package provides a new experience for querying a Ponder app over HTTP. It's an SQL-based alternative to the GraphQL API. Read more.
@ponder/react
The @ponder/react package uses @ponder/client and Tanstack Query to provide reactive live queries. Read more.
publicClients
Custom API endpoint files now have access to a new "ponder:api" virtual module. This module contains the db object and a new publicClients object, which contains a Viem Public Client for each network. These clients use the transports defined in ponder.config.ts.
import { publicClients, db } from "ponder:api";
import schema from "ponder:schema";
import { Hono } from "hono";
const app = new Hono();
app.get("/account/:chainId/:address", async (c) => {
const chainId = c.req.param("chainId");
const address = c.req.param("address");
const balance = await publicClients[chainId].getBalance({ address });
const account = await db.query.accounts.findFirst({
where: eq(schema.accounts.address, address),
});
return c.json({ balance, account });
});
export default app;Custom log filters
The contracts.filter property now supports multiple log filters, and requires argument values. Read more.
0.8
Breaking changes
Database management
Ponder now requires the database schema to be explicitly specified with an environment variable or CLI flag. onchainSchema() is removed.
DATABASE_SCHEMA=my_schemaponder start --schema my_schemaRailway
Railway users should update the start command to include a database schema.
pnpm start --schema $RAILWAY_DEPLOYMENT_ID@ponder/core → ponder
New versions will be published to ponder and not @ponder/core.
pnpm remove @ponder/core
pnpm add ponder@/generated → ponder:registry
The virtual module @/generated was replaced with ponder:registry.
- import { ponder } from "@/generated";
+ import { ponder } from "ponder:registry";factory() function
The factory() function replaces the factory property in the contract config. The result should be passed to the address property.
import { createConfig } from "@ponder/core";
export default createConfig({
contracts: {
uniswap: {
factory: {
address: "0x1F98431c8aD98523631AE4a59f267346ea31F984",
event: getAbiItem({ abi: UniswapV3FactoryAbi, name: "PoolCreated" }),
parameter: "pool",
},
},
},
});ponder-env.d.ts
This release updates the ponder-env.d.ts file. The new file uses triple slash directives for less frequent updates.
pnpm codegenRemoved transactionReceipt.logs
The transactionReceipt.logs property was removed from the event object.
Removed redundant properties from event
The following properties were removed from the event object.
- event.log.blockNumber;
- event.log.blockHash;
- event.log.transactionHash;
- event.log.transactionIndex;
- event.transaction.blockNumber;
- event.transaction.blockHash;
- event.transactionReceipt.transactionHash;
- event.transactionReceipt.transactionIndex;All of the data is still available on other properties of the event object, such as event.transaction.hash or event.block.number.
New features
Account indexing
A new event source accounts is available. Accounts can be used to index transactions and native transfers to and from an address. Read more.
ponder:schema alias
The ponder:schema virtual module was added. It is an alias for ponder.schema.ts.
- import { accounts } from "../ponder.schema";
+ import { accounts } from "ponder:schema";It also contains a default export of all the exported table objects from ponder.schema.ts.
import schema from "ponder:schema";
const row = await db.insert(schema.accounts).values({
address: "0x7Df1", balance: 0n
});ponder db list
A new command was added for more visibility into which database schemas are being used.
$ ponder db list
│ Schema │ Active │ Last active │ Table count │
├───────────────┼──────────┼────────────────┼─────────────┤
│ indexer_prod │ yes │ --- │ 10 │
│ test │ no │ 26m 58s ago │ 10 │
│ demo │ no │ 1 day ago │ 5 │0.7
Breaking changes
This release includes several breaking changes.
Install & run codegen
pnpm add @ponder/core@0.7To ensure strong type safety during the migration, regenerate ponder-env.d.ts.
pnpm codegenMigrate ponder.schema.ts
Here's a table defined with the new schema definition API, which uses Drizzle under the hood.
import { onchainTable } from "@ponder/core";
export const accounts = onchainTable("account", (t) => ({
address: t.hex().primaryKey(),
daiBalance: t.bigint().notNull(),
isAdmin: t.boolean().notNull(),
graffiti: t.text(),
}));Key changes:
- Declare tables with the
onchainTablefunction exported from@ponder/core - Export all table objects from
ponder.schema.ts - Use
.primaryKey()to mark the primary key column - Columns are nullable by default, use
.notNull()to add the constraint - The
hexcolumn type now usesTEXTinstead ofBYTEA p.float()(DOUBLE PRECISION) was removed, uset.doublePrecision()ort.real()instead
The new onchainTable function adds several new capabilities.
- Custom primary key column name (other than
id) - Composite primary keys
- Default column values
Here's a more advanced example with indexes and a composite primary key.
import { onchainTable, index, primaryKey } from "@ponder/core";
export const transferEvents = onchainTable(
"transfer_event",
(t) => ({
id: t.text().primaryKey(),
amount: t.bigint().notNull(),
timestamp: t.integer().notNull(),
from: t.hex().notNull(),
to: t.hex().notNull(),
}),
(table) => ({
fromIdx: index().on(table.from),
})
);
export const allowance = onchainTable(
"allowance",
(t) => ({
owner: t.hex().notNull(),
spender: t.hex().notNull(),
amount: t.bigint().notNull(),
}),
(table) => ({
pk: primaryKey({ columns: [table.owner, table.spender] }),
})
);
export const approvalEvent = onchainTable("approval_event", (t) => ({
id: t.text().primaryKey(),
amount: t.bigint().notNull(),
timestamp: t.integer().notNull(),
owner: t.hex().notNull(),
spender: t.hex().notNull(),
}));Migrate indexing functions
This release updates the indexing function database API to offer a unified SQL experience based on Drizzle.
Here's an indexing function defined with the new API, which uses the table objects exported from ponder.schema.ts.
import { ponder } from "@/generated";
import { account } from "../ponder.schema";
ponder.on("ERC20:Transfer", async ({ event, context }) => {
await context.db
.insert(account)
.values({
address: event.args.from,
balance: 0n,
isOwner: false,
})
.onConflictDoUpdate((row) => ({
balance: row.balance - event.args.amount,
}));
});Key changes:
- Transition from ORM pattern
db.Account.create({ ... })to query builder patterndb.insert(accounts, { ... }) - Import table objects from
ponder.schema.ts - Replace
findManywithdb.sql.select(...)ordb.sql.query(...)
Here is a simple migration example to familiarize yourself with the API.
// Create a single allowance
await context.db.Allowance.create({
id: event.log.id,
data: {
owner: event.args.owner,
spender: event.args.spender,
amount: event.args.amount,
},
});Here is a reference for how to migrate each method.
// create -> insert
await context.db.Account.create({
id: event.args.from,
data: { balance: 0n },
});
await context.db.insert(account).values({ id: event.args.from, balance: 0n });
// createMany -> insert
await context.db.Account.createMany({
data: [
{ id: event.args.from, balance: 0n },
{ id: event.args.to, balance: 0n },
],
});
await context.db.insert(account).values([
{ id: event.args.from, balance: 0n },
{ id: event.args.to, balance: 0n },
]);
// findUnique -> find
await context.db.Account.findUnique({ id: event.args.from });
await context.db.find(account, { address: event.args.from });
// update
await context.db.Account.update({
id: event.args.from,
data: ({ current }) => ({ balance: current.balance + 100n }),
});
await context.db
.update(account, { address: event.args.from })
.set((row) => ({ balance: row.balance + 100n }));
// upsert
await context.db.Account.upsert({
id: event.args.from,
create: { balance: 0n },
update: ({ current }) => ({ balance: current.balance + 100n }),
});
await context.db
.insert(account)
.values({ address: event.args.from, balance: 0n })
.onConflictDoUpdate((row) => ({ balance: row.balance + 100n }));
// delete
await context.db.Account.delete({ id: event.args.from });
await context.db.delete(account, { address: event.args.from });
// findMany -> raw SQL select, see below
await context.db.Account.findMany({ where: { balance: { gt: 100n } } });
await context.db.sql.select().from(account).where(eq(account.balance, 100n));
// updateMany -> raw SQL update, see below
await context.db.Player.updateMany({
where: { id: { startsWith: "J" } },
data: { age: 50 },
});
await context.db.sql
.update(player)
.set({ age: 50 })
.where(like(player.id, "J%"));Finally, another migration example for an ERC20 Transfer indexing function using upsert.
import { ponder } from "@/generated";
ponder.on("ERC20:Transfer", async ({ event, context }) => {
const { Account, TransferEvent } = context.db;
await Account.upsert({
id: event.args.from,
create: {
balance: BigInt(0),
isOwner: false,
},
update: ({ current }) => ({
balance: current.balance - event.args.amount,
}),
});
});Migrate API functions
- Removed
c.tablesin favor of importing table objects fromponder.schema.ts
New features
Arbitrary SQL within indexing functions
The new context.db.sql interface replaces the rigid findMany method and supports any valid SQL select query.
import { desc } from "@ponder/core";
import { account } from "../ponder.schema";
ponder.on("...", ({ event, context }) => {
const result = await context.db.sql
.select()
.from(account)
.orderBy(desc(account.balance))
.limit(1);
});0.6.0
Breaking changes
Updated viem to >=2
This release updates the viem peer dependency requirement to >=2. The context.client action getBytecode was renamed to getCode.
pnpm add viem@latestSimplified Postgres schema pattern
Starting with this release, the indexed tables, reorg tables, and metadata table for a Ponder app are contained in one Postgres schema, specified by the user in ponder.config.ts (defaults to public). This means the shared ponder schema is no longer used. (Note: The ponder_sync schema is still in use).
This release also removes the view publishing pattern and the publishSchema option from ponder.config.ts, which may disrupt production setups using horizontal scaling or direct SQL. If you relied on the publish pattern, please get in touch on Telegram and we'll work to get you unblocked.
New features
Added /ready, updated /health
The new /ready endpoint returns an HTTP 200 response once the app is ready to serve requests. This means that historical indexing is complete and the app is indexing events in realtime.
The existing /health endpoint now returns an HTTP 200 response as soon as the process starts. (This release removes the maxHealthcheckDuration option, which previously governed the behavior of /health.)
For Railway users, we now recommend using /ready as the health check endpoint to enable zero downtime deployments. If your app takes a while to sync, be sure to set the healthcheck timeout accordingly. Read the Railway deployment guide for more details.
0.5.0
Breaking changes
hono peer dependency
This release adds Hono as a peer dependency. After upgrading, install hono in your project.
pnpm add hono@latestNew features
Introduced custom API endpoints
This release added support for API functions. Read more.
0.4.0
Breaking changes
This release changes the location of database tables when using both SQLite and Postgres. It does not require any changes to your application code, and does not bust the sync cache for SQLite or Postgres.
New database layout
Please read the new docs on direct SQL for a detailed overview.
SQLitePonder now uses the .ponder/sqlite/public.db file for indexed tables. Before, the tables were present as views in the .ponder/sqlite/ponder.db. Now, the.ponder/sqlite/ponder.db file is only used internally by Ponder.
Ponder now creates a table in the public schema for each table in ponder.schema.ts. Before, Ponder created them as views in the ponder schema.
Isolation while running multiple Ponder instances against the same database also works differently. Before, Ponder used a schema with a pseudorandom name if the desired schema was in use. Now, Ponder will fail on startup with an error if it cannot acquire a lock on the desired schema.
This also changes the zero-downtime behavior on platforms like Railway. For more information on how this works in 0.4, please reference:
After upgrading to 0.4, you can run the following Postgres SQL script to clean up stale tables and views created by 0.3 Ponder apps.
Note: This script could obviously be destructive, so please read it carefully before executing.
DO $
DECLARE
view_name TEXT;
schema_name_var TEXT;
BEGIN
-- Drop all views from the 'ponder' schema
FOR view_name IN SELECT table_name FROM information_schema.views WHERE table_schema = 'ponder'
LOOP
EXECUTE format('DROP VIEW IF EXISTS ponder.%I CASCADE', view_name);
RAISE NOTICE 'Dropped view "ponder"."%"', view_name;
END LOOP;
-- Drop the 'ponder_cache' schema
EXECUTE 'DROP SCHEMA IF EXISTS ponder_cache CASCADE';
RAISE NOTICE 'Dropped schema "ponder_cache"';
-- Find and drop any 'ponder_instance_*' schemas
FOR schema_name_var IN SELECT schema_name AS schema_name_alias FROM information_schema.schemata WHERE schema_name LIKE 'ponder_instance_%'
LOOP
EXECUTE format('DROP SCHEMA IF EXISTS %I CASCADE', schema_name_var);
RAISE NOTICE 'Dropped schema "%"', schema_name_var;
END LOOP;
END $;0.3.0
Breaking changes
Moved SQLite directory
Note: This release busted the SQLite sync cache.
The SQLite database was moved from the .ponder/store directory to .ponder/sqlite. The old .ponder/store directory will still be used by older versions.
Moved Postgres sync tables
Similar to SQLite, the sync tables for Postgres were moved from the public schema to ponder_sync. Now, Ponder does not use the public schema whatsoever.
This change did NOT bust the sync cache; the tables were actually moved. This process emits some WARN-level logs that you should see after upgrading.
0.2.0
Breaking changes
Replaced p.bytes() with p.hex()
Removed p.bytes() in favor of a new p.hex() primitive column type. p.hex() is suitable for Ethereum addresses and other hex-encoded data, including EVM bytes types. p.hex() values are stored as bytea (Postgres) or blob (SQLite). To migrate, replace each occurrence of p.bytes() in ponder.schema.ts with p.hex(), and ensure that any values you pass into hex columns are valid hexadecimal strings. The GraphQL API returns p.hex() values as hexadecimal strings, and allows sorting/filtering on p.hex() columns using the numeric comparison operators (gt, gte, le, lte).
New features
Cursor pagination
Updated the GraphQL API to use cursor pagination instead of offset pagination. Note that this change also affects the findMany database method. See the GraphQL pagination docs for more details.
0.1
Breaking changes
Config
- In general,
ponder.config.tsnow has much more static validation using TypeScript. This includes network names incontracts, ABI event names for the contracteventandfactoryoptions, and more. - The
networksandcontractsfields were changed from an array to an object. The network or contract name is now specified using an object property name. Thenamefield for both networks and contracts was removed. - The
filterfield has been removed. To index all events matching a specific signature across all contract addresses, add a contract that specifies theeventfield without specifying anaddress. - The
abifield now requires an ABI object that has been asserted as const (cannot use a file path). See the ABIType documentation for more details.
Schema
- The schema definition API was rebuilt from scratch to use a TypeScript file
ponder.schema.tsinstead ofschema.graphql. Theponder.schema.tsfile has static validation using TypeScript. - Note that it is possible to convert a
schema.graphqlfile into aponder.schema.tsfile without introducing any breaking changes to the autogenerated GraphQL API schema. - Please see the
design your schemaguide for an overview of the new API.
Indexing functions
event.paramswas renamed toevent.argsto better match Ethereum terminology norms.- If a contract uses the
eventoption, only the specified events will be available for registration. Before, all events in the ABI were available. context.modelswas renamed tocontext.db- Now, a read-only Viem client is available at
context.client. This client uses the same transport you specify inponder.config.ts, except all method are cached to speed up subsequent indexing. - The
context.contractsobject now contains the contract addresses and ABIs specified inponder.config.ts, typed as strictly as possible. (You should not need to copy addresses and ABIs around anymore, just usecontext.contracts). - A new
context.networkobject was added which contains the network name and chain ID that the current event is from.
Multi-chain indexing
- The contract
networkfieldponder.config.tswas upgraded to support an object of network-specific overrides. This is a much better DX for indexing the same contract on multiple chains. - The options that you can specify per-network are
address,event,startBlock,endBlock, andfactory. - When you add a contract on multiple networks, Ponder will sync the contract on each network you specify. Any indexing functions you register for the contract will now process events across all networks.
- The
context.networkobject is typed according to the networks that the current contract runs on, so you can write network-specific logic likeif (context.network.name === "optimism") { …
Vite
- Ponder now uses Vite to transform and load your code. This means you can import files from outside the project root directory.
- Vite's module graph makes it possible to invalidate project files granularly, only reloading the specific parts of your app that need to be updated when a specific file changes. For example, if you save a change to one of your ABI files,
ponder.config.tswill reload because it imports that file, but your schema will not reload. - This update also unblocks a path towards concurrent indexing and granular caching of indexing function results.